Opté por Cowrie como el componente clave de mi infraestructura de detección de
tráfico no deseado. Cowrie es un fantástico honeypot de interacción media/alta diseñado para registrar intentos de fuerza bruta e
interacciones con un shell remoto por parte de atacantes, tanto a través de SSH como de Telnet. Cowrie es muy popular entre investigadores y entusiastas
debido a su óptima combinación de capacidades y facilidad de uso. Es un programa de código abierto y está respaldado por una activa
comunidad liderada por Michel Oosterhof, el mantenedor, creador y desarrollador principal del
proyecto.
1. Elección del sistema anfitrión del honeypot
El primer paso es la elección de un sistema Linux donde instalar el honeypot. Dado que Cowrie es muy eficiente en su consumo de recursos, elegí
inslarlo en un Raspberry Pi 400.
2. Instalación de las dependencias del sistema
Instala las dependencias del sistema en el ordenador anfitrión (host)) de Cowrie:
$ sudo apt-get install git python3-virtualenv libssl-dev libffi-dev build-essential libpython3-dev python3-minimal authbind virtualenv
3. Creación de la cuenta de usuario
Aunque instalar una cuenta de usuario sin contraseña no es absolutemente requerido, los autores de Cowrie lo recomiendan encarecidamente por motivos de
seguridad:
$ sudo adduser --disabled-password cowrie
Adding user 'cowrie' ...
Adding new group 'cowrie' (1002) ...
Adding new user 'cowrie' (1002) with group 'cowrie' ...
Changing the user information for cowrie
Enter the new value, or press ENTER for the default
Full Name []:
Room Number []:
Work Phone []:
Home Phone []:
Other []:
Is the information correct? [Y/n]
$ sudo su - cowrie
4. Obtención del código de Cowrie
Clona el repositorio de código cowrie albergado en GitHub:
$ git clone http://github.com/cowrie/cowrie
Cloning into 'cowrie'...
remote: Counting objects: 2965, done.
remote: Compressing objects: 100% (1025/1025), done.
remote: Total 2965 (delta 1908), reused 2962 (delta 1905), pack-reused 0
Receiving objects: 100% (2965/2965), 3.41 MiB | 2.57 MiB/s, done.
Resolving deltas: 100% (1908/1908), done.
Checking connectivity... done.
$ cd cowrie
5. Instalación de un entorno virtual de Python
Técnicamente hablando, este paso no es necesario, pero se recomienda para garantizar que las actualizaciones de paquetes en el sistema host de Cowrie
no causen incompatibilidades:
$ pwd
/home/cowrie/cowrie
$ python -m venv cowrie-env
New python executable in ./cowrie/cowrie-env/bin/python
Installing setuptools, pip, wheel...done.
Después de instalar el entorno virtual, actívalo e instala los paquetes requeridos:
$ source cowrie-env/bin/activate
(cowrie-env) $ python -m pip install --upgrade pip
(cowrie-env) $ python -m pip install --upgrade -r requirements.txt
6. Configuración de Cowrie
La configuración de Cowrie se guarda en el fichero cowrie/etc/cowrie.cfg. Para operar con una configuración
estándar, no es necesario cambiar nada. De forma predeterminada, Cowrie acepta tráfico a través de SSH. Para que el honeypot acepte
también tráfico por Telnet, envie sus datos a Splunk (más información sobre esto abajo) y cambie los puertos predeterminados (22 y 23),
tenemos que modificar el fichero de configuración de la siguiente forma:
[telnet]
enabled = true
...
[output_splunk]
enabled = true
...
[proxy]
backend_ssh_port = 2022
backend_telnet_port = 2023
También quería cambiar las configuraciones de usuario predeterminadas y la lista de credenciales aceptadas para iniciar sesiones en el shell
remoto. Estos cambios se realizan modificando el fichero cowrie/etc/userdb.txt. Cada línea del fichero consta de tres campos
separados por un carácter ::
- El primer campo es el nombre de usuario.
- El segundo campo no se utiliza por ahora y siempre es
x.
- El tercer campo es la especificación de las contraseñas aceptadas por el usuario.
Como ejemplo, los siguientes valores configuran un nombre de usuario
admin que acepta todas las contraseñas excepto 1)
sólo caracteres numéricos, 2) la palabra
admin en minúsculas y 3) la palabra
honeypot insensible a mayúsculas y minúsculas:
admin:x:!admin
admin:x:!/^[0-9]+$/
admin:x:!/honeypot/i
admin:x:*
7. Personalización de Cowrie
Opcionalmente, puedes cambiar la apariencia de la interfaz de Cowrie para que parezca más realista. Varios archivos te permiten hacer eso:
-
En
cowrie/etc/cowrie.cfg, puedes cambiar, por ejemplo, el nombre del sistema (hostname) que se muestra en el shell
remoto, el indicador de usuario (prompt), el nombre de usuario y contraseña de Telnet, la respuesta del commando uname,
la versión de SSH mostrada por el comando ssh -V, etc.
hostname = appsrv02
...
prompt = root>
...
telnet_username_prompt_regex = (\n|^)ubuntu login: .*
telnet_password_prompt_regex = .*Password: .*
...
kernel_version = 3.2.0-4-amd64
kernel_build_string = #1 SMP Debian 3.2.68-1+deb7u1
hardware_platform = x86_64
operating_system = GNU/Linux
...
ssh_version = OpenSSH_7.9p1, OpenSSL 1.1.1a 20 Nov 2018
- En
cowrie/honeyfs/etc/issue, puedes cambiar el mensaje anterior a la sesión de inicio.
- En
cowrie/honeyfs/etc/motd, puedes cambiar el mensaje posterior a la sesión de inicio.
- En
cowrie/honeyfs/proc/cpuinfo, puedes cambiar el número y tipo de procesadores del sistema simulado.
- En
cowrie/honeyfs/proc/meminfo, puedes cambiar asignaciónn y el uso de memoria del sistema simulado.
- En
cowrie/honeyfs/proc/version, puedes cambiar las versiones del núcleo (kernel) de Linux y
gcc.
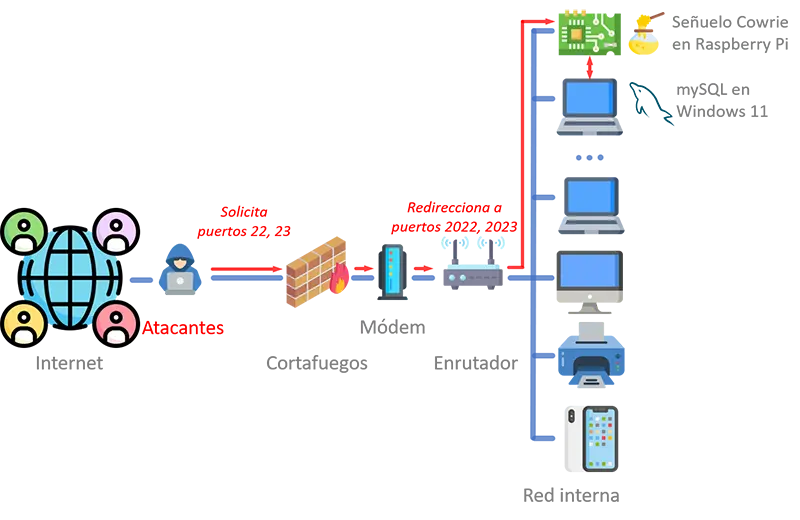
8. Redirección de puertos
Como vimos anteriormente, configuré Cowrie para aceptar tráfico SSH a través del puerto 2022 y tráfico Telnet a través del
puerto 2023. Para preservar la fidelidad del señuelo, abrí los puertos 22 y 23 en mi enrutador y redirigí su tráfico a los puertos 2022 y 2023,
respectivamente, en el sistema en el que instalé Cowrie.
9. Inicializacón de Cowrie
Inicializa el honeypot invocando el fichero ejecutable cowrie/bin/cowrie que forma parte de la distribución de Cowrie.
Se conservará cualquier entorno virtual existente si se activa; de lo contrario, Cowrie intentará cargar el entorno virtual
cowrie-env que creamos anteriormente:
bin/cowrie start
Activating virtualenv "cowrie-env"
Starting cowrie with extra arguments [] ...
Escogí MySQL como almacén de los datos generados por Cowrie porque es una tecnología potente y madura, ofrece excelentes funcionalidades de búsqueda
y manipulación de datos basadas en APIs, se puede instalar localmente y, lo mejor de todo, es de código abierto y gratis. Al principio, usé una solución
basada en Splunk Enterprise. Aunque Splunk es una plataforma propietaria, es gratis si mantienes el volumen de generación de datos por debajo de 500 MB al día.
Splunk me funconó bien durante seis meses, pero un día el señuelo detectó un pico de ataques que se tradujo en un volumen de 2.5 TB en un día.
En ese momento experimenté en carne propia el lado oscuro del modelo de negocios freemium y las práctias de gestión de usuarios de Splunk que distan mucho
de ser ideales: «paga o te bloqueamos los datos durante un mes». Como ambas opciones me resultaron inaceptables, decidí abandonar Splunk y migrar mis datos a
MySQL. La decisión y sus ramificaciones han sido enteramente positivas y satisfactorias. Si tienes curiosidad por saber cómo preparé mi anterior entorno señuelo
basado en Splunk, puedes consultar mis notas de instalación y configuración aquí.
Cowrie ofrece una serie de instrucciones para enviar los datos directamente desde el honeypot
a una base de datos MySQL. Esas instrucciones son considerablemente más breves y sencillas que las que encontrarás en esta página, y son un buen punto de partida.
Al final, opté por una configuración a medida que me permitiera ir más allá de las prestaciones básicas proporcionadas por Cowrie. Específicamente,
necesitaba la flexibilidad de poder importar una versión modificada de la fuente de datos de Cowrie y poder analizar los datos por medio de una API. También necesitaba poder
correr el servidor MySQL en un sistema huesped de Windows diferente al huesped del señuelo. Las instrucciones en esta página propocionan esas prestaciones.
1. Masajeado de datos
Puede usar la información de Cowrie tal y como viene del honeypot en forma de archivos JSON diarios. Se trata, básicamente, de una fuente de
datos basada en eventos, donde cada sesión o interacción no deseada con el señuelo se desglosa en la serie de eventos que constituyen un ataque:
por ejemplo, conexión, intento de inicio de sesión, ejecución de comandos en la terminal, creación o carga/descarga de archivos al
señuelo, desconexión, etc.
Opté por una visión alternativa del tráfico no deseado basada en sesiones, no en eventos. Para ello, convertí la fuente de datos original
de Cowrie en una nueva donde la unidad básica de información, que posteriormente se almacenará como una fila en una base de datos SQL, es la
sesión, no el evento. Esto requiere fusionar todos los eventos correspondientes a la misma sesión en una sola fila. Este trabajo fue parte de la
normalización de datos que realicé cuando usaba Splunk como repositorio de datos. Como recordatorio, la normalización de datos es el proceso
de reorganizar o "masajear" los datos para que sea más fácil y rápido trabajar con ellos. Implica reducir o eliminar la redundancia de datos y
garantizar que las dependencias entre ellos se implementen de forma que tenga en cuenta las limitaciones de la base de datos que los contiene. Esto permite consultar
y analizar los datos con mayor facilidad y velocidad. Splunk no utiliza una base de datos convencional, por lo que la normalización que dio lugar a la nueva
fuente basada en sesiones fue todo lo que necesitábamos. Pero MySQL, nuestra nueva solución de almacenamiento de datos, utiliza una base de datos SQL.
Para los datos SQL, el proceso de normalización a menudo requiere dividir tablas grandes en tablas más pequeñas y vincularlas mediante relaciones.
Y eso es exactamente lo que tuve que hacer. Para entender por qué, veamos un aspecto clave de nuestra nueva fuente de datos basada en sesiones:
-
Algunos de los campos de las sesiones tienen un único valor:
| Capo en la fuente original |
Campo en la nueva fuente |
Descripciónn |
| |
dst_asn |
Nuevo - ASN de la dirección de IP de destino (es decir, la del señuelo) proporcionada por MaxMind |
| |
dst_country |
Nuevo - País de la dirección de IP de destino proporcionada por MaxMind |
| dst_ip |
dst_ip |
Dirección de IP de destino |
| dst_port |
dst_port |
Puerto de destino |
| duration |
duration |
Duración de la sesión en segundos |
| input |
commands |
Secuencia de comandos ejecutados en el terminal |
| protocol |
protocol |
Protocolo de red por el que se envió el tráfico no deseado |
| sensor |
sensor |
Nombre del señuelo o honeypot |
| session |
session |
Identificador de sesión único |
| |
src_asn |
Nuevo - ASN de la dirección de IP de origen (es decir, la del atacante o hacker) proporcionada por MaxMind |
| |
src_country |
Nuevo - País de la dirección de IP de origen proporcionada por MaxMind |
| src_ip |
src_ip |
Dirección de IP de origen |
| src_port |
src_port |
Puerto de origen |
| timestamp |
timestamp |
Fecha y hora de inicio de la interacción no deseada |
| |
traffic_type |
Nuevo - ¿Es el tráfico no deseado un escaneo (scan) o un ataque (attack)? |
-
Algunos de los campos son listas con más de un valor:
| Campo en la fuente original |
Campo en la nueva fuente |
Descripción |
| (login) success|failed |
attempt_logins |
Lista de resultados de intentos de accesso |
| password |
attempt_passwords |
Lista de contraseñas en intentos de acceso |
| username |
attempt_usernames |
Lista de nombres de usuario en intentos de acceso |
| |
attempt_credentials |
Nuevo - Lista de usuario\0contraseña credenciales en intentos de acceso |
| hash |
malware_hashes |
Lista de hashes de ficheros maliciosos |
| filename, outfile |
malware_sites |
Lista de direcciones URL de ficheros maliciosos |
| |
malware_types |
Nuevo - Lista de tipos de ficheros maliciosos: cargados (upload), descargados (download), o redireccionados (redir) |
| (tcpip) dst_ip |
tcpip_dst_ips |
Lista de direcciones de IP de destino TCP/IP |
| (tcpip) dst_port |
tcpip_dst_ports |
Lista depuertos de destino TCP/IP |
| (tcpip) src_ip |
tcpip_src_ips |
Lista de direcciones de IP de origen TCP/IP |
| (tcpip) src_port |
tcpip_src_ports |
Lista de puertos de origen TCP/IP |
| ttylog |
ttylog_names |
Lista de archivos de registro TTY conteniendo las interacciones de un ataque |
| sha256, url |
vtlookup_files |
Lista de hashes o URLs (muestras sospechosas) escaneados por VirusTotal |
| is_new |
vtlookup_new |
Lista de clasificación como conocidas o desconocidas de las muestras maliciosas escaneadas por VirusTotal |
| positives |
vtlookup_positives |
Lista de número de proveedores de información de VirusTotal que clasificaron las muestras como maliciosas |
| total |
vtlookup_scans |
Lista de número de proveedores de información de VirusTotal que escanearon las muestras sospechosas |
Los campos de valor único son fáciles de manejar y no requieren procesamiento adicional: se implementan directamente como columnas en una tabla de
base de datos SQL. Sin embargo, las reglas SQL prohíben o restringen considerablemente el uso de listas en las columnas de las tablas. La solución
a este problema es realizar una normalización SQL de los datos en la fuente de Cowrie de la siguiente manera:
-
Crea una tabla principal sessions cuyas columnas son los campos de valor único.
-
Crea una tabla secundaria para cada campo de valor de lista. Estas tablas contienen los valores individuales de sus respectivas listas. Las tablas secundarias se
vinculan a la tabla principal mediante una clave foránea que hace referencia a la columna
session de la tabla principal
sessions. En total, construí cinco tablas secundarias:
-
attempts para almacenar los valores de
attempt_logins, attempt_passwords,
attempt_usernames y attempts_credentials
-
malware para almacenar los valores de
malware_hashes, malware_sites y
malware_types
-
tcpip para almacenar los valores de
tcpip_dst_ips, tcpip_dst_ports,
tcpip_src_ips y tcpip_src_ports
-
ttylogs para almacenar los valores de
ttylogs
-
vtlookups para almacenar los valores de
vtlookup_files, vtlookupp_new,
vtlookup_positives y vtlookup_scans
Observa que el campo commands es algo anómalo. Técnicamente, es una lista de comandos de Linux separados por comas.
Sin embargo, como actualmente lo uso como una sola entidad, lo trato como un campo de valor único cuyo valor en una cadena larga de caracteres (es decir,
como una columna en la tabla principal). Es posible que cambie esta disposición más adelante e implemente el campo de comandos como una nueva tabla secundaria,
desglosando los comandos individuales
Finalmente, decidí omitir en la nueva fuente de datos de Cowrie algunos campos de la fuente original que añaden poco valor a mi investigación.
2. Instalación de MySQL
El primer paso es la instalación de la versión MySQL para Windows disponible en el área de descargas
de la comunidad de MySQL. Cuando realicé mi instalación, la última versión del instalador para Windows era 8.0.36. El proceso de instalación es sencillo:
Abre el instalador de MySQL para Windows.
- Elige el tipo de instalación Custom para ser capaz de escoger los componentes MySQL que quieres instalar.
- Además de MySQL Server, asegúrate de que instalas MySQL Router si quieres tener acceso a tus datos a través de una API (cubriremos esto más
adelante). En mi caso, también instalé MySQL Shell y MySQL Workbench para disponer de interfaces con las que configurar la base de datos y manipular la
información. Workbench, Shell y Router están disponibles como Applications en el diálogo de instalación. Como no necesitaba los MySQL Connectors
(ODBC, C++ y Python), no los instalé.
- El instalador ofrece múltiples versions de cada uno de los productos seleccionados. Yo sólo instalé la más reciente (8.0.36).
- Después de que el instalador descargue e instale los componentes MySQL que has escogido, procederá a la configuración de MySQL Server y MySQL Router.
- El primer paso de configuración es la selección del tipo de servidor MySQL y los parámetros de conexión en red. Hay tres tipos de servidores, cada uno con
más requisitos de memoria que el anterior: Development Computer, Server Computer y Dedicated Computer. Originalmente escogí Development Computer,
pero cambié a Server Computer cuando empecé a experimentar problemas de rendimiento.
- Acepta los parámetros de configuración de redes que se te ofrecen por defecto.
- En el siguiente paso, tienes que escoger un método de autentificación. Acepta la recomendación de usar contraseñas seguras y escoge una contraseña
para la cuenta root de MySQL.
- A continuación, configura el servicio de Windows y los permisos de los ficheros del servidor aceptando los parámetros predefinidos.
- Finalmente, configura MySQL Router aceptando de nuevo los valores predefinidos.
Tras el proceso de instalación anterior, el servicio de MySQL para Windows y las aplicaciones
MySQL Shell y
MySQL Workbench arrancarán automáticamente.
3. Creación de la base de datos MySQL para Cowrie
En esta sección se enumeran los pasos para crear una base de datos MySQL que más tarde utilizaremos para albergar los datos recopilados por el señuelo Cowrie:
- Si la aplicación MySQL Workbench no está corriendo, arráncala.
- Bajo MySQL Connections, observarás una conexión predefinida con el nombre "Local instance MySQL80". Haz clic en ella e introduce tu contraseña para la
cuenta root en el servidor de MySQL.
- Selecciona la pestaña Schemas en el menú de la izquierda.
- Haz clic en el icono Create a new schema in the connected server situado en la barra de tareas en la parte de arriba de la ventana. El icono representa una base de datos con un
símbolo de suma sobreimpuesto.
- Escoge un nombre para el nuevo esquema (yo elegí
cowrie_normalized para el mío), haz clic en el botón Apply (dos veces) y luego en
Finish.
-
A continuación, tienes que crear las tablas de la base de datos:
-
Haz clic doble en el esquema que acabas de crear y luego haz clic en el icono Create a new table in the active schema in connected server, que tiene
forma de una tabla con el signo de suma.
- Introduce un nombre para la tabla principal; la mía es
sessions.
-
Repite los dos pasos anteriores para crear las cinco tablas secundarias:
credentials, malware,
tcpip, ttylogs y vtlookups.
-
A continuación, tienes que diseñar tu nueva tabla especificando el nombre y tipo de dato de cada una de las columnas (campos). Reflejando el nuevo
esquema de datos, configuré mi tabla de MySQL así:
--
-- Estructura de la tabla principal `sessions`
--
`session_id` int NOT NULL, UNIQUE, PRIMARY, AUTO_INCREMENT
`session` varchar(12) NOT NULL, UNIQUE
`commands` longtext
`dst_ip` varchar(15) NOT NULL
`dst_port` int NOT NULL
`dst_asn` int DEFAULT NUL
`dst_country` varchar(45) DEFAULT NUL
`duration` float NOT NULL
`protocol` varchar(6) NOT NULL
`sensor` varchar(48) NOT NULL
`src_ip` varchar(15) NOT NULL
`src_port` int NOT NULL
`src_asn` int NOT NULL
`src_country` varchar(45) NOT NULL
`timestamp` timestamp(6) NOT NULL, UNIQUE
`traffic_type` varchar(6) NOT NULL
--
-- Estructura de la tabla secundaria `attempts`
--
`attempt_credentials` varchar(513) NOT NULL
`attempt_id` int NOT NULL, UNIQUE, PRIMARY, AUTO_INCREMENT
`attempt_login` varchar(5) NOT NULL
`attempt_password` varchar(256) DEFAULT NULL
`attempt_session` varchar(12) NOT NULL, UNIQUE, FOREIGN KEY REFERENCES `sessions` (`session`)
`attempt_username` varchar(256) NOT NULL
--
-- Estructura de la tabla secundaria `malware`
--
`malware_hash` varchar(64) NOT NULL
`malware_id` int NOT NULL, UNIQUE, PRIMARY, AUTO_INCREMENT
`malware_session` varchar(12) NOT NULL, FOREIGN KEY REFERENCES `sessions` (`session`)
`malwaer_site` varchar(45) DEFAULT NULL
`malware_type` varchar(8) NOT NULL
--
-- Estructura de la tabla secundaria `tcpip`
--
`tcpip_dst_ip` varchar(256) DEFAULT NULL
`tcpip_dst_port` int DEFAULT NULL
`tcpip_id` int NOT NULL, UNIQUE, PRIMARY, AUTO_INCREMENT
`tcpip_session` varchar(12) NOT NULL, FOREIGN KEY REFERENCES `sessions` (`session`)
`tcpip_src_ip` varchar(256) DEFAULT NULL
`tcpip_src_port` int DEFAULT NULL
--
-- Estructura de la tabla secundaria `ttylogs`
--
`ttylog_id` int NOT NULL, UNIQUE, PRIMARY, AUTO_INCREMENT
`ttylog_name` varchar(96) NOT NULL
`ttylog_session` varchar(12) NOT NULL, FOREIGN KEY REFERENCES `sessions` (`session`)
--
-- Estructura de la tabla secundaria `vtlookups`
--
`vtlookup_file` varchar(64) NOT NULL
`vtlookup_id` int NOT NULL, UNIQUE, PRIMARY, AUTO_INCREMENT
`vtlookup_new` varchar(5) NOT NULL
`vtlookup_positives` int NOT NULL
`vtlookup_scans` int NOT NULL
`vtlookup_session` varchar(12) NOT NULL, FOREIGN KEY REFERENCES `sessions` (`session`)
Hay una columna en la tabla MySQL para cada uno de los campos en la fuente basada en sesiones de Cowrie, y una columna adicional *_id
que sirve como clave primaria de la base de datos. Di a esa columna el atributo auto-incremento y, como veremos más adelante, añadí
lógica de programación para asegurarme de que no haya huecos en sus valores.
-
Una vez que estés satisfecho con el diseño de tu tabla, hac clic en el botón Apply (dos veces) y, finalmente, haz clic en Finish.
¡Enhorabuena! Ya tienes una base de datos MySQL lista para aceptar los datos del señuelo Cowrie.
4. Instalación de Apache, PHP y phpMyAdmin
Este paso no es un requisito absoluto pero si, como yo, quieres tener la capacidad de visualizar tus datos en MySQL a través de una interfaz HTTP y estás acostumbrado a usar
phpMyAdmin para configurar MySQL, lo deberías considerar. Quizá la forma más fácil de instalar phpMyAdmin en Windows es por medio de la
distribución XAMPP (Cross Apache MariaDB PHP Perl) de Apache Friends. Puedes descargar su instalador para Windows
de su sitio web. Cuando instalé mi copia, la última versión disponible era la 8.2.12. La instalación es sencilla:
- Descarga y abre el instalador para Windows de XAMPP.
- Si se te muestra un aviso de que el control de cuentas de usuario (UAC) de Windows puede interferir con la instalación de XAMPP, haz clic en OK para eliminarlo.
- Selecciona los components que deseas instalar. No necesito Mercury Mail Server, Tomcat, Perl, Webalizer, o Fake Sendmail, y ya tenía instalado
MySQL (de la sección 1 de arriba) y FileZilla FTP Server. Apache y PHP son requisitos y se instalan siempre, así que sólo seleccioné
phpMyAdmin.
- Acepta todos los otros parámetros de instalación predeterminados.
- Si aparece una notificación del Firewall de Windows Defender indicando que el firewall ha boqueado el servidor HTTP de Apache, haz clic en Allow access para
continuar.
- Haz clic en Finish para terminar la instalación.
Si todo fue bien, Apache, PHP y phpMyAdmin, junto con el muy últil
Panel de Control de XAMP, estarán instalados en tu sistema. Ahora tenemos que conectar la anterior
instalación de MySQL con la reciente instalación de phpMyAdmin:
- Abre el fichero de configuración de phpMyAdmin (por defecto, está instalado como
C:\xampp\phpMyAdmin\config.inc.php) y cambia los
parámetros de autentificación para reflejar la configuración de MySQL:
/* Tipo e información de autentificación */
$cfg['Servers'][$i]['auth_type'] = 'config';
$cfg['Servers'][$i]['user'] = 'root';
$cfg['Servers'][$i]['password'] = 'TU_CONTRASEÑA_PARA_LA_CUENTA_ROOT_DEL_SERVIDOR_MYSQL';
$cfg['Servers'][$i]['extension'] = 'mysqli';
$cfg['Servers'][$i]['AllowNoPassword'] = true;
$cfg['Lang'] = '';
/* Usuario para prestaciones avanzadas */
/* $cfg['Servers'][$i]['controluser'] = 'pma'; */
/* $cfg['Servers'][$i]['controlpass'] = ''; */
- Añade las siguienes líneas al fichero de configuración de pphMyAdin y sálvalo:
/* Elimina el siguiente error: The phpMyAdmin configuration storage is not completely configured, some extended features have been deactivated. */
$cfg['PmaNoRelation_DisableWarning'] = true;
- Abre el Panel de Control de XAMPP. Las opciones para MySQL, FileZilla, Mercury y Tomcat están inactivas en gris ya que no fueron instaladas,
pero la opción de Apache está disponible.
- Haz clic en el botón Start para arrancar Apache.
- Ahora puedes abrir tu navegador favorito y navegar, indistintamente, a
localhost o a 127.0.0.1. En ese momento, se
abrirá la página de inicio de XAMPP en tu servidor local de Apache.
- Haz clic en el enlace a phpMyAdmin en la parte de arriba de la página. Se mostrará otra página con el esquema
cowrie y la
tabla normalized_traffic que creaste en la sección 2 de arriba.
5. Carga de los datos de Cowrie en la base de datos mySQL
En lugar de implementar una solución sofisticada basada en intermediación de mensajes, decidí construir un sistema más sencillo aprovechando ciertas
características de la arquitectura de Cowrie. Como el señuelo guarda el tráfico no deseado en ficheros diarios en formato JSON, desarollé un programa
que se ejecuta automáticamente una vez al día por medio del programador de tareas de Windows. Su lógica general es como sigue:
- Adquisición de la lista de eventos registrados por Cowrie a partir de los ficheros diarios en JSON.
-
Conversión de la fuente de datos nativa de Cowrie basada en eventos en una nueva fuente de datos basada en sesiones tal y como se describió
anteriormente.
-
Conversión de la lista de sesiones de la nueva fuente de su formato JSON a formato CSV (valores separados por comas) y creación de seis ficheros
CSV, uno por cada tabla:
sessions.csv, attempts.csv, malware.csv,
tcpip.csv, ttylogs.csv y vtscans.csv.
-
Generación de pequeño programa de instrucciones SQL para importar los datos. Por ejemplo, el programa
sessions.sql
que ingiere los datos de sessions.csv en la tabla sessions tiene el sigiente código:
SET @maxid = (SELECT COALESCE(MAX(session_id), 0) + 1 FROM cowrie.sessions);
SET @sql = CONCAT('ALTER TABLE cowrie.sessions AUTO_INCREMENT = ', @maxid);
PREPARE st FROM @sql;
EXECUTE st;
LOAD DATA INFILE 'sessions.csv'
IGNORE INTO TABLE cowrie.sessions
FIELDS TERMINATED BY ','
ENCLOSED BY '"'
ESCAPED BY ''
LINES TERMINATED BY '\n'
IGNORE 1 LINES
(session,commands,dst_ip,dst_port,dst_country,dst_asn,duration,protocol,sensor,src_ip,src_port,src_country,src_asn,timestamp,type);
Las primeras cuatro líneas obtienen el valor máximo en la columna session_id de nuestra tabla MySQL, que corresponde con el número del
último registro (sesión) en la tabla. Dicho valor, incrementado en uno, es utilizado como el valor de auto-incremento en la siguiente ingesta de datos.
Si no lo asignamos explícitamente, es casi seguro que el próximo valor de auto-incremento escogido por MySQL para la siguiente importación de datos sea más
que 1 mayor que el valor de auto-incremento del último registro del día anterior. Dicho de otra forma, las primeras cuatro líneas de SQL aseguran que no haya
huecos en los valores de la columna id.
Las instrucciones SQL que siguen se encargan de importar los datos de Cowrie en formato CSV del fichero sessions.csv. La instrucción
IGNORE ordena a MySQL a continuar importando filas del fichero CSV incluso cuando se ha detectado un error. En este caso, se generará
un mensaje de diagnóstico. Otras instrucciones indican que los caracteres para separar los campos, agrupar los valores de los campos y terminar las líneas son, respecivamente,
,, " y \n, y que no es necesario procesar los caracteres que tienen significado especial.
La instrucción IGNORE 1 LINES se proporciona para que MySQL ignore la primera línea, es decir, la cabecera con los nombres de los campos, que se
especifican en la última línea.
-
Importación de la información en formato CSV a la base de datos MySQL mediante la ejecución del script
sessions.sql desde MySQL Shell:
mysqlsh -uroot -h localhost --sql < sessions.sql
-
Repite los pasos anteriores para importar los datos en las tablas secundarias:
mysqlsh -uroot -h localhost --sql < attempts.sql
mysqlsh -uroot -h localhost --sql < malware.sql
mysqlsh -uroot -h localhost --sql < tcpip.sql
mysqlsh -uroot -h localhost --sql < ttylogs.sql
mysqlsh -uroot -h localhost --sql < vtlookups.sql
Si has seguido las instrucciones hasta aquí, tendrás la información registrada por Cowrie —formateada en sesiones fáciles de leer y
analizar— disponible en una base de datos MySQL. Tómate unos minutos para celebrar lo conseguido.
6. Configuración del servicio REST de mySQL (MRS)
Llegado a este punto, tenemos una base de datos MySQL cargada con datos de conexiones de internet no deseadas recogidos por un señuelo Cowrie. Podemos interactuar con la base de datos por medio
de tres distintas interfaces: MySQL Shell, MySQL Workbench y phpMyAdmin. En el siguiente paso, añadiremos una cuarta forma de visualizar and manipular los datos
por medio de una extensión del popular editor Visual Studio Code. En realidad, esto no es obligatorio, pero simplificará mucho la próxima tarea de configuración
de una API basada en el el servicio REST de MySQL (MRS). Brevemente, MRS is una tecnología que proporciona un acceso rápido y seguro por HTTP a datos albergados en MySQL.
MRS está construido como una prestación de MySQL Router y ofrece la posibilidad de publicar servicios web basados en REST para interactuar con soluciones MySQL como, en
nuestro caso, bases de datos. En mi caso particular, utilizo la API básica de MRS para extraer programáticamente los datos de Cowrie almacenados en MySQL, lo que es una parte
importante de mi proceso de análisis de datos. Aunque MRS se puede configurar directamente desde MySQL Shell, es mucho más fácil hacerlo desde la extensión
de Visual Studio Code. Doy por hecho que estás familiarizado con el editor Visual Studio Code, así que no cubriremos
su instalación aquí.
- Empieza abriendo Visual Studio Code.
- Selecciona el icono de Extensions en el menú de herramientas de la izquierda.
- Busca "MySQL Shell for VS Code".
- Haz clic en el botón Install al lado del resultado MySQL Shell for VS Code de la búsqueda.
- Si se muestra un diálogo preguntando si te fías de los autores de la extensión, haz clic en Trust Workspace & Install para seguir.
-
Tras el paso anterior, aparecerá un nuevo icono con la imagen de Sakila, el delfín del logo de MySQL, en el menú de la izquierda. Haz clic en
él.
- Haz clic en Next un par de veces para instalar un certificado. Si aparece una notificación de seguridad de Windows, haz clic en Yes para confirmar que quieres
instalar el certificado.
- Verás un mensaje indicando que la instalación se completó correctamente. Haz clic en Reload VS Code Window para continuar.
- Haz clic en el botón + New Connection para crear una conexión con la base de datos MySQL.
-
En el diálogo Database Connection Configuration, haz clic on la pesta&ntildde;a Basic. Introduce
MySQL
como el valor del parámetro Database Type y localhost para Host Name. Especifica un nombre y detalles para la
conexión en los parámetros Caption y Description; yo escogí Cowrie y
Conexión a la base de datos normalizada Cowrie. Introduce root como User Name y el
nombre del esquema que creaste anteriormente en el paso 2 (es decir, cowrie_normalized) como Default Schema. Deja todos los
otros paámetros con sus valores predefinidos y haz clic en OK.
-
Verás una nueva entrada Cowrie bajo DATABASE COONNECTIONS en la parte izquierda. Haz clic en ella y teclea la contraseña del usuario
root.
-
Despué de la autentificación, haz clic con el botón derecho del ratón en la conexión Cowrie y selecciona Configure
instance for MySQL REST Service Support.
- En el diálogo de MySQL REST Service, accepta todos los valores predefinidos y haz clic en OK.
-
Aparecerán varias nuevas entradas bajo la conexión a la base de datos Cowrie. Una de ellas es MySQL Rest Service. Haz clic en ella
con el botón derecho del ratón y selecciona Add REST Service....
- En el diálogo de configuración de MySQL REST Service, introduce una ruta de fichero, que servirá como nombre del endpoint del
servicio. Yo elegí
/honeypot en mi configuración. Acepta todos los restantes valores predeterminados y haz clic en
OK. El nuevo endpoint aparecerá bajo Cowrie\MySQL REST Service.
-
Ahora que ya hemos configurado el endpoint del servicio REST de MySQL, tenemos que hacer que los datos fluyan por él. Para ello, tenemos que conectar
el esquema y la tabla de la base de datos con el servicio REST.
- Haz clic con el botón derecho del ratón en DATABASE CONNECTIONS\Cowrie\cowrie_normalized y selecciona Add Schema to REST Service.
-
En el diálogo de configuración de MySQL REST Schema, introduce una ruta de fichero/endpoint en REST Schema Path. Yo escogí
/v1 para seguir construyendo el URL de la API de forma que cumpla el consenso de nomenclatura de APIs RESTfuk. Haz clic en OK.
-
Haz clic con el botón derecho del ratón en DATABASE CONNECTIONS\Cowrie\cowrie_normalized\Tables\sessions y selecciona Add Database Object
to REST Service.
-
En el diálogo de configuración de MySQL REST Object, introduce una ruta de fichero/endpoint en REST Object Path como, por ejemplo,
/sessions. Elimina la selección de Auth. Required. El diálogo de configuración mostrará el
mapeo de los campos de la tabla MySQL a los nombres de la API. Observa que 1) tanto la labla primaria como las secundarias están disponibles para el mapeo, y
que 2) los nombres de los objetos de la API siguen la convención camelCase.
-
Repite los dos pasos anteriores para crear los endpoints
/attempts, /malware,
/tcpip, /ttylogs y /vtlookups.
- El resultado de las acciones anteriores es el siguiente mapeado:
Tabla Principal "sessions" API
-------------------------- ---
commands commands
dst_asn dstAsn
dst_country dstCountry
dst_ip dstIp
dst_port dstPort
duration duration
sessin_id sessionId
protocol protocol
sensor sensor
session session
src_asn srcAsn
src_country srcCountry
src_ip srcIp
src_port srcPort
timestamp timestamp
traffic_type trafficType
Tabla Secundaria "attempts" API
--------------------------- ---
attempt_credentials attemptCredentials
attempt_id attemptId
attemtp_login attemptLogin
attempt_password attemptPassword
attempt_username attemptUsername
attempt_session attemptSession
Tabla Secundaria "malware" API
-------------------------- ---
malware_hash malwareHash
malware_id malwareId
malware_session malwareSession
malware_site malwareSite
malware_type malwareType
Tabla Secundaria "tcpip" API
------------------------ ---
tcpip_dst_ip tcpipDstIP
tcpip_dst_port tcpipDstPort
tcpip_id tcpipId
tcpip_session tcpipSession
tcpip_src_ip tcpipSrcIp
tcpip_src_port tcpipSrcPort
Tabla Secundaria "ttylogs" API
-------------------------- ---
ttylog_id ttylogId
ttylog_name ttylogName
ttylog_session ttylogSession
Tabla Secundaria "vtlookups" API
---------------------------- ---
vtlookup_file vtlookupFile
vtlookup_id vtlookupId
vtlookup_new vtlookupNew
vtlookup_positives vtlookupPositives
vtlookup_scans vtlookupScans
vtlookup_session vtlookupSession
En el mismo diálogo, se presenta la opción de escoger qué campos se hacen disponibles a través de la API. Acepta todos, que es la
opción predefinida. Finalmente, haz clic en OK. En este momento, los endpoints con acceso a los datos de Cowrie en la base de datos
están listos para ser usados.
-
Haz clic con el botón derecho del ratón en DATABASE CONNECTIONS\Cowrie\MySQL REST Service y selecciona Bootstrap Local MySQL Router
Instance. Esto hará que el servicio de MySQL Router arranque. Se te pedirá que introduzcas un código de web JSON (JWT).
-
Para terminar, haz clic con el botón derecho del ratón en DATABASE CONNECTIONS\Cowrie\MySQL REST Service and select Start Local MySQL
Router Instance.
¡Y así hemos llegado a la meta! Nuestros datos están ahora disponibles en la URL
https://localhost:8443/honeypot/v1
a través de los siguientes
endpoints:
/sessions/attempts/malware/tcpip/ttylogs/vtlookups
7. Verifiación de la API de MRS
Como paso final, procederemos a verificar que los datos de Cowrie que importamos en la base de datos MySQL son accesibles en los endpoints. Desde Visual
Studio Code, haz clic con el botón derecho del ratón en DATABASE CONNECTIONS\Cowrie\MySQL REST Service\honeypot\v1\sessions y selecciona
Open REST Object Request Path in Web Browser. Tu navegador de internet abrirá una nueva pestaña mostrando, en formato JSON, las 25 primeras
sesiones capturadas por Cowrie.
Para que esto funcione, asegúrate de que MySQL Router está corriendo. Puedes arrancar MySQL Router desde un terminal de comandos con la
ayuda del siguiente script de Bash:
#!/bin/bash
declare +i -r MSRCONF="c:/Users/TU_NOMBRE_DE_USUARIO_DE_WINDOWS/AppData/Roaming/MySQL/mysqlsh-gui/plugin_data/mrs_plugin/router_configs/1/mysqlrouter"
declare +i -r MSRPATH="c:/Users/TU_NOMBRE_DE_USUARIO_DE_WINDOWS/.vscode/extensions/oracle.mysql-shell-for-vs-code-1.14.2-win32-x64/router"
declare +i pid=""
export PATH="${PATH}:${MSRPATH}/lib"
export ROUTER_PID="${MSRCONF}/mysqlrouter.pid"
pid=`ps -W | grep mysqlrouter | awk '{print $1}'`
if [ ! "${pid}" = "" ]
then
echo "MySQL Router ya está corriendo con PID = ${pid}"
exit 0
else
"${MSRPATH}/bin/mysqlrouter.exe" -c "${MSRCONF}/mysqlrouter.conf" > /dev/null 2>&1 &
disown %-
pid=`ps -W | grep mysqlrouter | awk '{print $1}'`
if [ ! "${pid}" = "" ]
then
echo "MySQL Router está corriendo con PID = ${pid}"
exit 0
else
echo "Error: MySQL Router no pudo arrancar"
exit 1
fi
fi
Puedes terminar el servicio
MySQL Router con el seguiente programa:
#!/bin/bash
declare +i -r MSRCONF="c:/Users/TU_NOMBRE_DE_USUARIO_DE_WINDOWS/AppData/Roaming/MySQL/mysqlsh-gui/plugin_data/mrs_plugin/router_configs/1/mysqlrouter"
declare +i pid=""
pid=`ps -W | grep mysqlrouter | awk '{print $1}'`
if [ ! "${pid}" = "" ]
then
echo "MySQL Router está corriendo con PID = ${pid}"
env kill -f ${pid} > /dev/null 2>&1
pid=`ps -W | grep mysqlrouter | awk '{print $1}'`
if [ "${pid}" = "" ]
then
rm -f ${MSRCONF}/mysqlrouter.pid
echo "MySQL Router ya no está corriendo"
exit 0
else
echo "Error: MySQL Router no pudo terminar"
exit 1
fi
else
echo "MySQL Router no está corriendo"
exit 0
fi
También podemos testar la API utilizando el comando curl desde una ventana de terminal or un script de shell.
La lista siguiente proporciona ejemplos de invocaciones del comando curl para extraer información recogida por Cowrie por
medio de la API del servicio REST de MySQL:
# Muestra las primeras 25 sesiones de Cowrie
curl -s -k 'https://localhost:8443/honeypot/v1/sessions' | jq
# Muestra los primeros 25 escaneos, filtrado en servidor
curl -s -k 'https://localhost:8443/honeypot/v1/sessions' -G --data-urlencode 'q={"type":"scan"}' | jq
# Muestra los primeros 25 ataques, filtrado en servidor
curl -s -k 'https://localhost:8443/honeypot/v1/sessions' -G --data-urlencode 'q={"type":"attack"}' | jq
# Muestra los primeros 25 ataques con acceso exitoso, filtrado en servidor
curl -s -k 'https://localhost:8443/honeypot/v1/attempts' -G --data-urlencode 'q={"login":"true"}' | jq
# Muestra los primeros 25 ataques con acceso exitoso, filtrado en cliente
curl -s -k 'https://localhost:8443/honeypot/v1/sessions' | jq '.items[] | select(.credentials?[]?.login == "true")'
# Muestra los primeros 25 ataques con acceso fallido, filtrado en cliente
curl -s -k 'https://localhost:8443/honeypot/v1/sessions' | jq '.items[] | select(.credentials? | length > 0 and all(.login == "false"))'
# Muestra las sesiones entre la 10.001 y la 10.500, filtrado en servidor
curl -s -k 'https://localhost:8443/honeypot/v1/sessions' -G --data-urlencode 'offset=10000&limit=500' | jq
# Muestra la sesión con número 12.345, filtrado en servidor
curl -s -k 'https://localhost:8443/honeypot/v1/sessions' -G --data-urlencode 'q={"id":12345}' | jq
# Muestra las primeras 25 sesiones que se originaron desde direcciones IP operando desde España, filtrado en servidor
curl -s -k 'https://localhost:8443/honeypot/v1/sessions' -G --data-urlencode 'q={"srcCountry":"Spain"}' | jq
# Muestra las primeras 25 sesiones que se originaron desde direcciones IP operando desde Singapur o Francia, filtrado en servidor
curl -s -k 'https://localhost:8443/honeypot/v1/sessions' -G --data-urlencode 'q={"$or":[{"srcCountry":"Singapore"},{"srcCountry":"France"}]}' | jq
Esto es todo. Ya estás listo para analizar la información recogida por el señuelo Cowrie. ¡Te deseamos una buena caza de hackers!
Referencia: Gramática de filtrado de MRS en JSON
El último ejemplo en la sección anterior muestra cómo combinar cláusulas de filtrado utilizando un operador lógico (en el ejemplo,
$or). La especificación completa en JSON de la gramática de filtrado del servicio REST de MySQL es la siguiente:
FilterObject { orderby , asof, wmembers }
orderby
"$orderby": {orderByMembers}
orderByMembers
orderByProperty
orderByProperty , orderByMembers
orderByProperty
columnName : sortingValue
sortingValue
"ASC"
"DESC"
"-1"
"1"
-1
1
asof
"$asof": date
"$asof": "datechars"
"$asof": scn
"$asof": +int
wmembers
wpair
wpair , wmembers
wpair
columnProperty
complexOperatorProperty
columnProperty
columnName : string
columnName : number
columnName : date
columnName : simpleOperatorObject
columnName : complexOperatorObject
columnName : [complexValues]
columnName
"\p{Alpha}[[\p{Alpha}]]([[\p{Alnum}]#$_])*$"
complexOperatorProperty
complexKey : [complexValues]
complexKey : simpleOperatorObject
complexKey
"$and"
"$or"
complexValues
complexValue , complexValues
complexValue
simpleOperatorObject
complexOperatorObject
columnObject
columnObject
{columnProperty}
simpleOperatorObject
{simpleOperatorProperty}
complexOperatorObject
{complexOperatorProperty}
simpleOperatorProperty
"$eq" : string | number | date
"$ne" : string | number | date
"$lt" : number | date
"$lte" : number | date
"$gt" : number | date
"$gte" : number | date
"$instr" : string
"$ninstr" : string
"$like" : string
"$null" : null
"$notnull" : null
"$between" : betweenValue
"$like": string
betweenValue
[null , betweenNotNull]
[betweenNotNull , null]
[betweenRegular , betweenRegular]
betweenNotNull
number
date
betweenRegular
string
number
date
string
JSONString
number
JSONNumber
date
{"$date":"datechars"}
scn
{"$scn": +int}
datechars is an RFC3339 date format in UTC (Z)
JSONString
""
" chars "
chars
char
char chars
char
any-Unicode-character except-"-or-\-or-control-character
\"
\\
\/
\b
\f
\n
\r
\t
\u four-hex-digits
JSONNumber
int
int frac
int exp
int frac exp
int
digit
digit1-9 digits
- digit
- digit1-9 digits
frac
. digits
exp
e digits
digits
digit
digit digits
e
e
e+
e-
E
E+
E-